|
I am a senior algorithm engineer at VisLab (an Ambarella Inc. company), where I work on 3D reconstruction for self-driving cars. I got my PhD in computer vision from Università degli Studi di Parma, while collaborating with Ambarella Inc. research teams in Italy and Taiwan. I was also a visiting scholar at NYCU, working on knowledge distillation and neural network compression. Previously, I was a software engineer at YAPE, designing full-stack autonomous navigation algorithms for a two-wheeled delivery robot. I hold a MSc in robotics engineering from Università degli Studi di Genova and Ecole Centrale de Nantes (double degree), as well as a BSc in control engineering from Politecnico di Milano. Email / Google Scholar / LinkedIn / GitHub |

|
|
I am broadly interested in computer vision and machine learning, especially in self-driving scenarios. The goal of my research is to combine geometry and learning for efficient, large-scale 3D understanding with cheap sensors. |

|
Marco Orsingher PhD Thesis, 2024 Thesis / BibTeX A collection of previous works, with additional details, visualizations and experiments, as well as the proper context on how they fit into my research goals. |
|
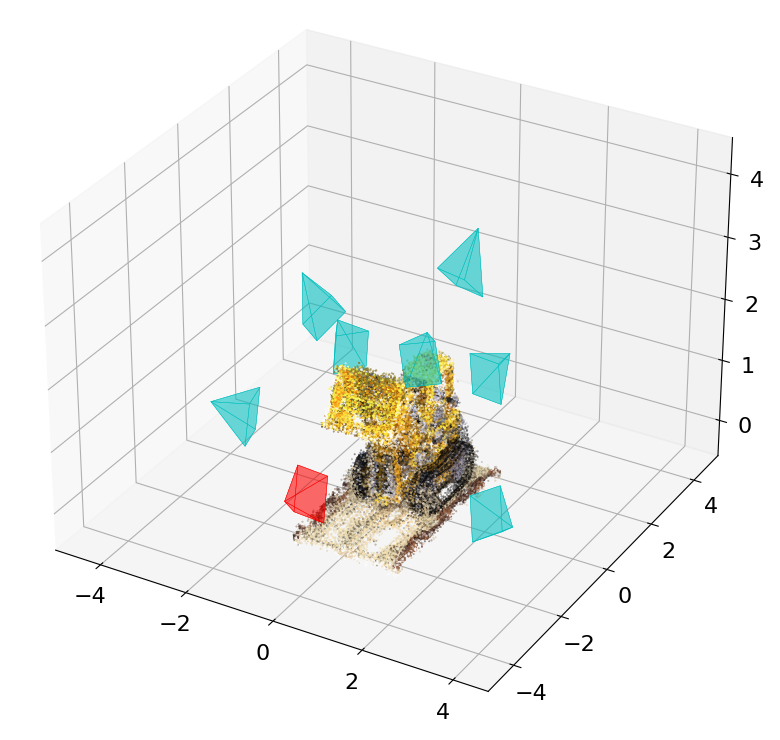
Marco Orsingher, Anthony Dell'Eva, Paolo Zani, Paolo Medici, Massimo Bertozzi VISAPP, 2024 Paper / Video / Code / BibTeX We analyze the sampling efficiency of NeRF and present two strategies to optimize it, given a limited training budget. |

|
Marco Orsingher, Paolo Zani, Paolo Medici, Massimo Bertozzi ECCV Workshop, 2022 Paper / Video / BibTeX We use classical 3D reconstruction as pseudo-supervision for training NeRF and obtain much cleaner surfaces. |

|
Anthony Dell'Eva (*), Marco Orsingher (*), Massimo Bertozzi (*Equal Contribution) 3DV, 2022 (Oral Presentation) Project Page / Paper / Video / Code / BibTeX We show that Transformers can learn to generate point clouds with arbitrary resolution from sparse raw data. |

|
Marco Orsingher, Paolo Zani, Paolo Medici, Massimo Bertozzi IEEE IV, 2022 Paper / BibTeX We propose a framework for monocular 3D reconstruction that combines visual SLAM, multi-scale PatchMatch MVS with planar priors and confidence-based graph optimization. |
|
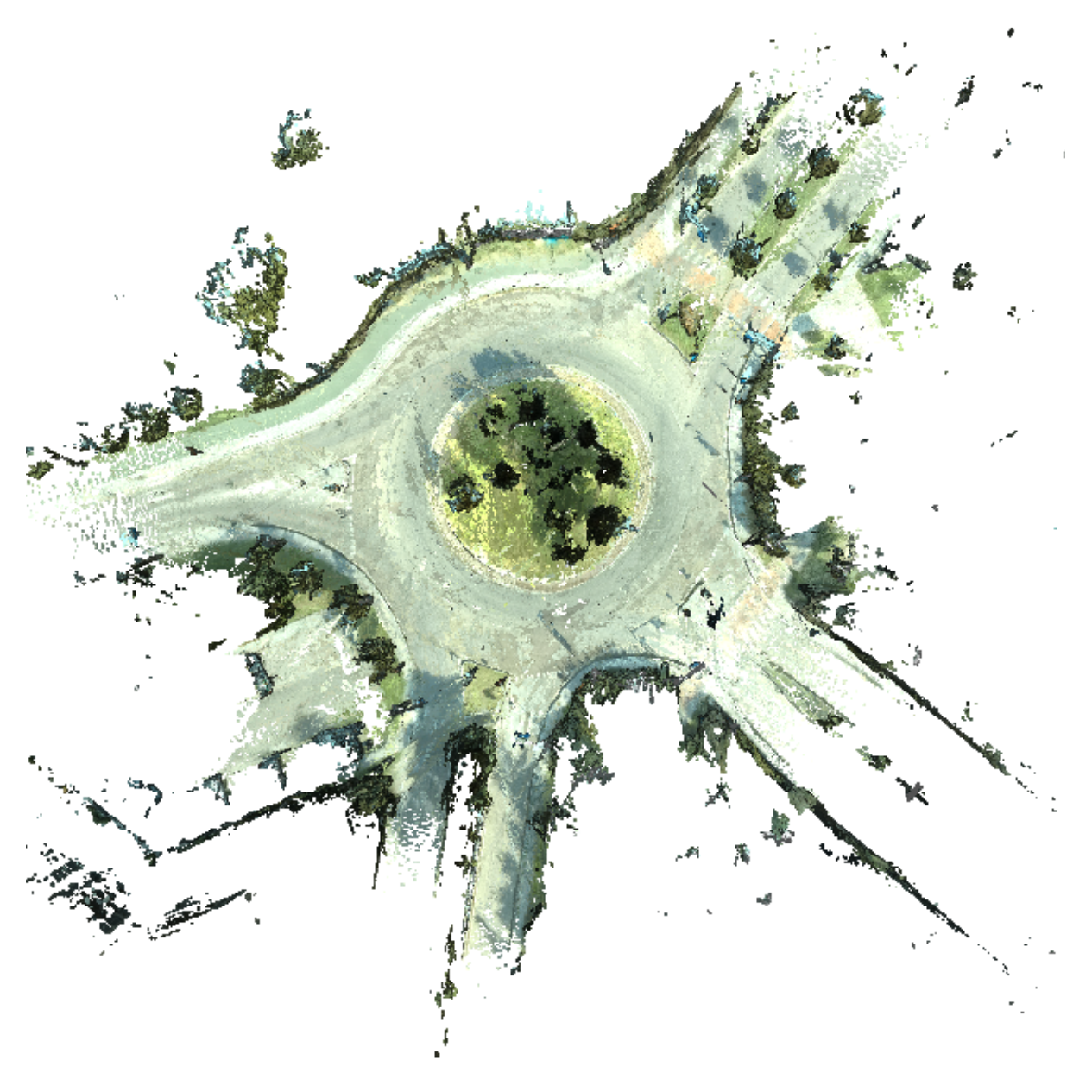
Marco Orsingher, Paolo Zani, Paolo Medici, Massimo Bertozzi ICIAP, 2021 (Oral Presentation) Paper / Video / BibTeX We design a view selection algorithm that scales linearly with the number of clusters and allows to reconstruct efficiently entire cities. |